Here is a series called Popular Algorithmics, originally featured on Tumbld Thoughts. A tour of various algorithmic approaches, highlighted with useful links.
The
RANSAC (Random Sample Consensus) Algorithm [1, 2] is an adaptive method to detect outliers by dividing the sample datapoints into "inliers" and "outliers". Treated in this way, the data can be incorporated into a model that exhibits minimial error. RANSAC is also robust to outliers, which might be useful for dealing with heavy-tailed and other non-normal (e.g. Gaussian) distributions.
RANSAC was developed for and used extensively in computer vision research [3]. A MATLAB toolbox specialized for image processing, but possibly amenable to other applications [4], is available from the MATLAB Exchange [3].
[1] Zuliani, M.
RANSAC for Dummies. August 13 (2012).
[2] Second picture is from: Zaman, T.
[3D] Ransac (get planes from point clouds). March 23 (2011).
[3]
RANSAC Algorithm for Image Processing. Stack Overflow (2011).
[4] Kowdle, A.
Parallel implementation of RAndom SAmple Consensus (RANSAC). Docstoc (2010).
[5] Chen, H.
RANSAC Toolbox. MATLAB Toolbox (2009).
Here are links to a feature by
David Ackley (University of New Mexico) on
robust-first computing in this month's
Communications of the ACM [1]. The argument: computing systems were originally designed to optimize efficiency (rather than robustness or adaptability), but at a cost of normal operation under novel or unexpected circumstances [2].
In this
YouTube video, Ackley uses a
bubblesort algorithm and alien symbols (e.g. unlabeled data) to demonstrate how and when a robust-first computing system can outperform systems designed using efficiency-first principles (e.g. your computer). This area of research also has broader implications for
understanding social and biological systems.
[1] Ackley, D. Viewpoint: Beyond Efficiency. Communications of the ACM, October (2013).
Open-access version here.
[2] Posey, B.M.
Demystifying the "Blue Screen of Death". Microsoft TechNet
AND Use a Windows Blue Screen of Death for Your WordPress 404 Error Page. How-to Geek.
Here are a few recent articles on the process and blind spots of applying algorithms to real-world problems. In [1],
Rhett Allain discusses the role of
random walk theory in modeling how two lost people find each other in a forest (or perhaps two ships in the night).
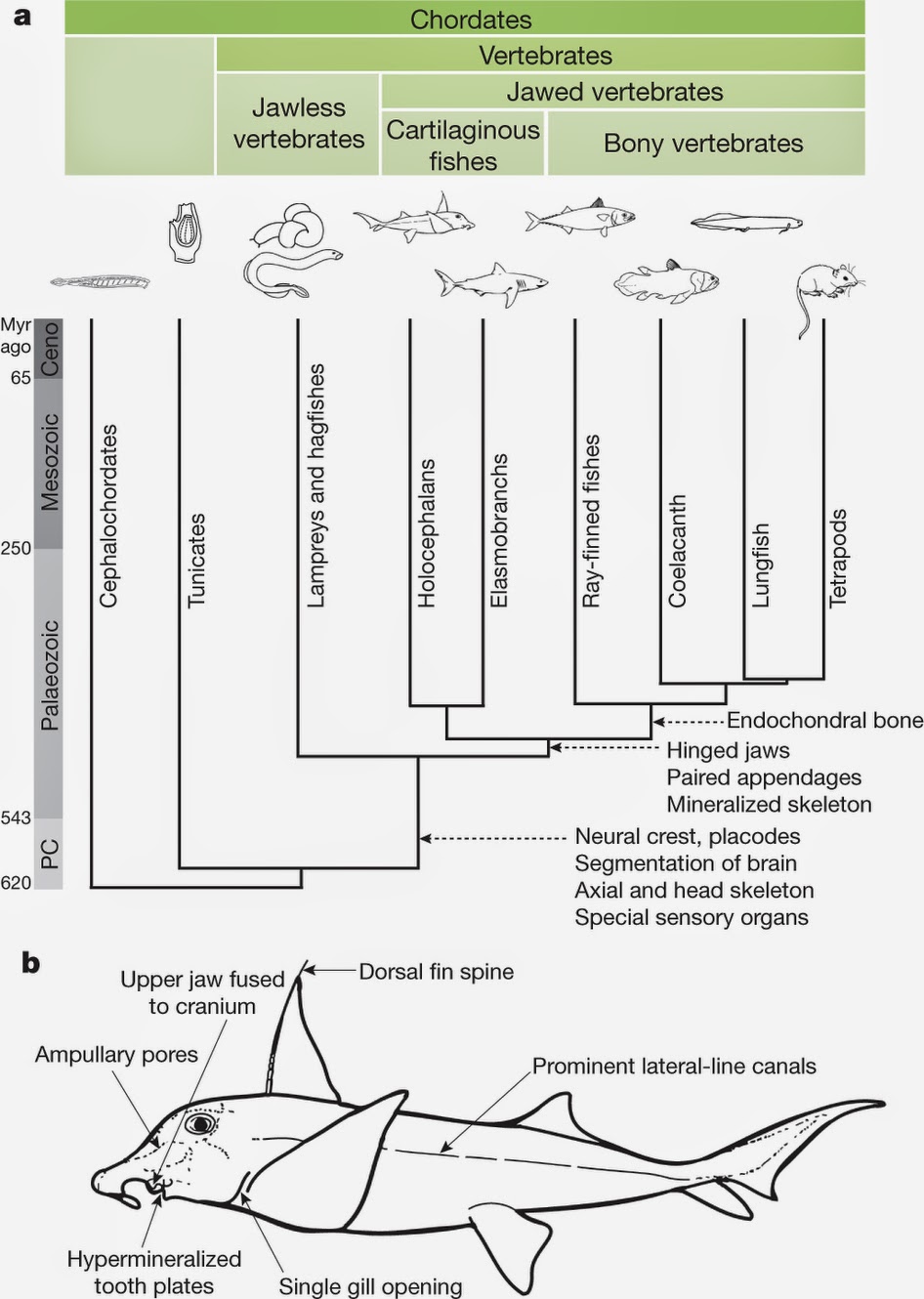
Here are some papers on shark genomes and machine learning. First up is a paper [1] in which the
Callorhinchus milii genome is sequenced and analyzed in an evolutionary framework. Possesses the slowest evolving vertebrate genome. The study also clarifies the phylogeny of chordates, and offers the intrepid reader 250 pages of supplemental material.
The second article and associated YouTube video [2, 3] explore the potential of deep learning, which perfect the art of AI as pattern recognition. Deep learning does increasingly better as data is added to the model. This overcomes the typical sigmoidal learning curve that characterizes traditional neural nets. But is the biological metaphor (learning machine as human brain) sufficient to push AI research to the next plateau?
[1] Venkatesh, B. et.al
Elephant shark genome provides unique insights into gnathosome evolution. Nature, doi:10.1038/nature12826 (2014).
[2] Jones, N.
The Learning Machines. Nature, 505, 146-148 (2014).
[3] Hinton, G.
Recent Developments in Deep Learning. Google TechTalks, March 19 (2010).
Here are a few readings and examples of the Hydra game [1-4]. This game play resembles
fast OLS and other tree-swapping phylogenetic reconstruction methods, but is a one player "
game against nature" that pits an autonomous player (who cuts off nodes one at a time) against a tree structure (that randomly generates new branches in response). This occurs much as it does in the
ancient Greek myth of the Hydra.
The interesting thing about this game is that the player cannot lose. Yet, in its pure form, neither can that player win. Rather, play continues infinitely until someone gives up -- according to a recent Quora post [3], it is one of the most counterintuitive results in Mathematics.
[1] Bauer, A.
The Hydra Game. Mathematics and Computation blog, February 2 (2008).
[2] Kirby, L. and Paris, J.
Accessible Independence Results for Peano Arithmetic. Bulletin of the London Mathematical Society, 14, 285-293 (1982).
[3]
Mathematics: what are some of the most counterintuitive mathematical results? Quora, March 27 (2014).
[4]
JAVA Application: Hydra game. Mathematics and Computation blog.
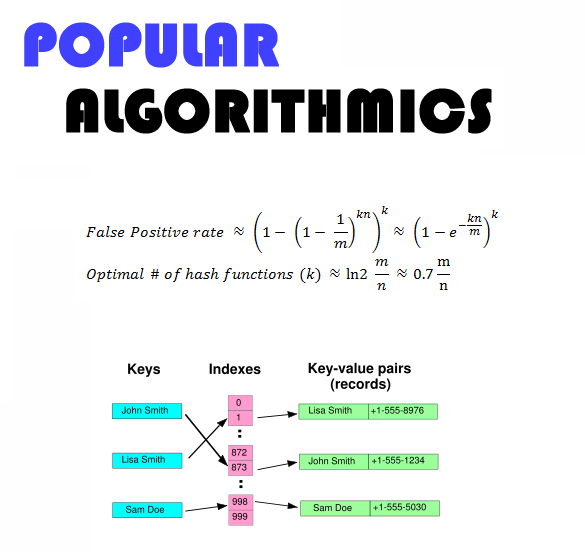
In this installment of Popular
Algorithmics, I present a short reading list covering a data
structure called the
Bloom
filter. The Bloom filter [1] is a complex probabilistic hash function
(e.g. maps semantic data to quantitative parameters) with a
membership query mechanism [2]. This is good for any kind of
set-based classification. In general, Bloom filters (particularly the
Murmur algorithm) are more efficient than the cryptographic hash used
in applications such as Bitcoin.
The probabilistic aspect of Bloom
filters mean that there is a deterministic false positive rate, which
can be tuned using a known number of input elements and hash
functions. Bloom filters can be applied to many types of problems,
including probabilistic verification [3] and bioinformatics [4].
[2] Holmes, A. Hadoop in Practice.
Manning Press (2012).
[4] Stranneheim, H., Kaller, M.,
Allander, T., Andersson, B., Arvestad, L., and Lundeberg, J.
Classification
of DNA sequences using Bloom filters. Bioinformatics, 26(13),
1595-1600 (2010).
Reading List:
Davies, J.
Bloom
Filters Overview. Jason Davies blog.
This installment of Popular Algorithmics is about
Bayesian Poisoning.
This is a heuristic strategy dating from the late 1990s, and involves
the intentional degradation of e-mail spam filters (typically
naive Bayesian models)
by spammers [1]. Poisoning strategies consist of Type I (intentionally
increasing the number of false positives) and Type II (embedding common
English words into a Spam message) attacks.
[1] Accettura, R.
Bayesian Span Filter Poisoning with RSS. Fun with Wordage blog, Januiary 29 (2007).
[2] Eckleberry, A.
What is the effect of Bayesian Poisoning? Security News blog, August 26 (2006).
This edition of Popular Algorithmics is a throwback to the 1990s. 7 August of 2014 was, according to Microsoft's "The Fire Hose"
blog, the
20th
anniversary of Microsoft's first website. Microsoft 1.0 was
originally
intended
to be a low-res information portal. Interesting foray into what
was to come.
Quasi-algorithmic word of the day:
sockpuppetry.
Sockpuppetry is the practice of inventing an deceptive identity for
one’s avatar in a virtual world. As with
Bayesian
Poisoning, sockpuppetry comes in two flavors: type I (a phony
persona different from the creator is used) and Type II (where
obfuscation of identity is the only requirement). Unlike Bayesian
Poisoning, however, Sockpuppetry can be done by a live person and not
a bot.
Seife, C.
The
Weird Reasons Why People Make Up False Identities on the Internet.
Wired, July 29 (2014) and the book
Virtual
Unreality.